

Deliverables (live at v0)
From personal frustration with cluttered voice memos, we explored:

How might we make voice memos more actionable?Can we automatically detect key points and speaker changes?
Is it possible to export these memos into editable, shareable formats?
Target Users: Startup founders, students, busy professionals (UX Researchers, Reporters)
Methods: 4 interviews, 12 survey responses
1.Deliver transcription of recorded/uploaded audio
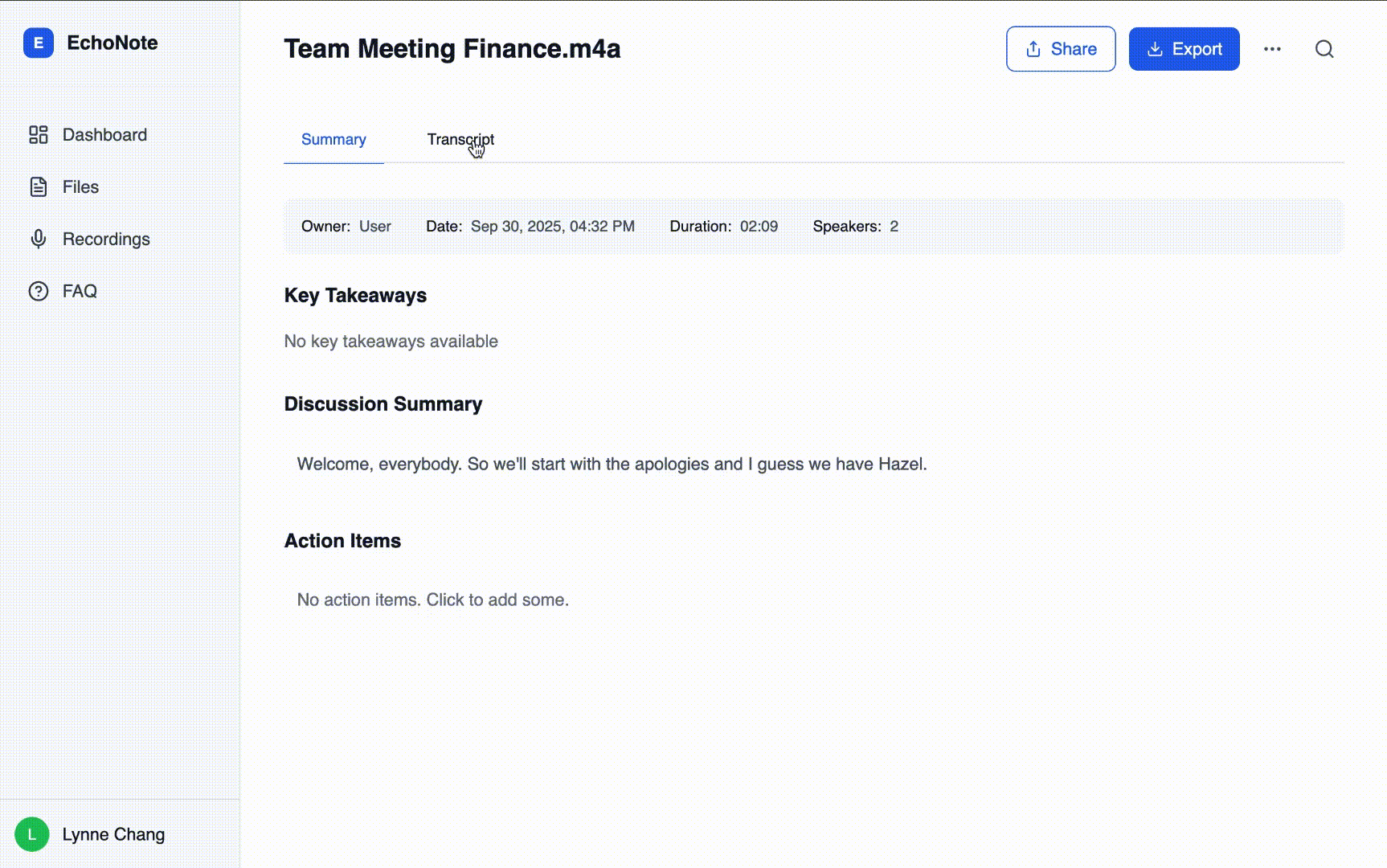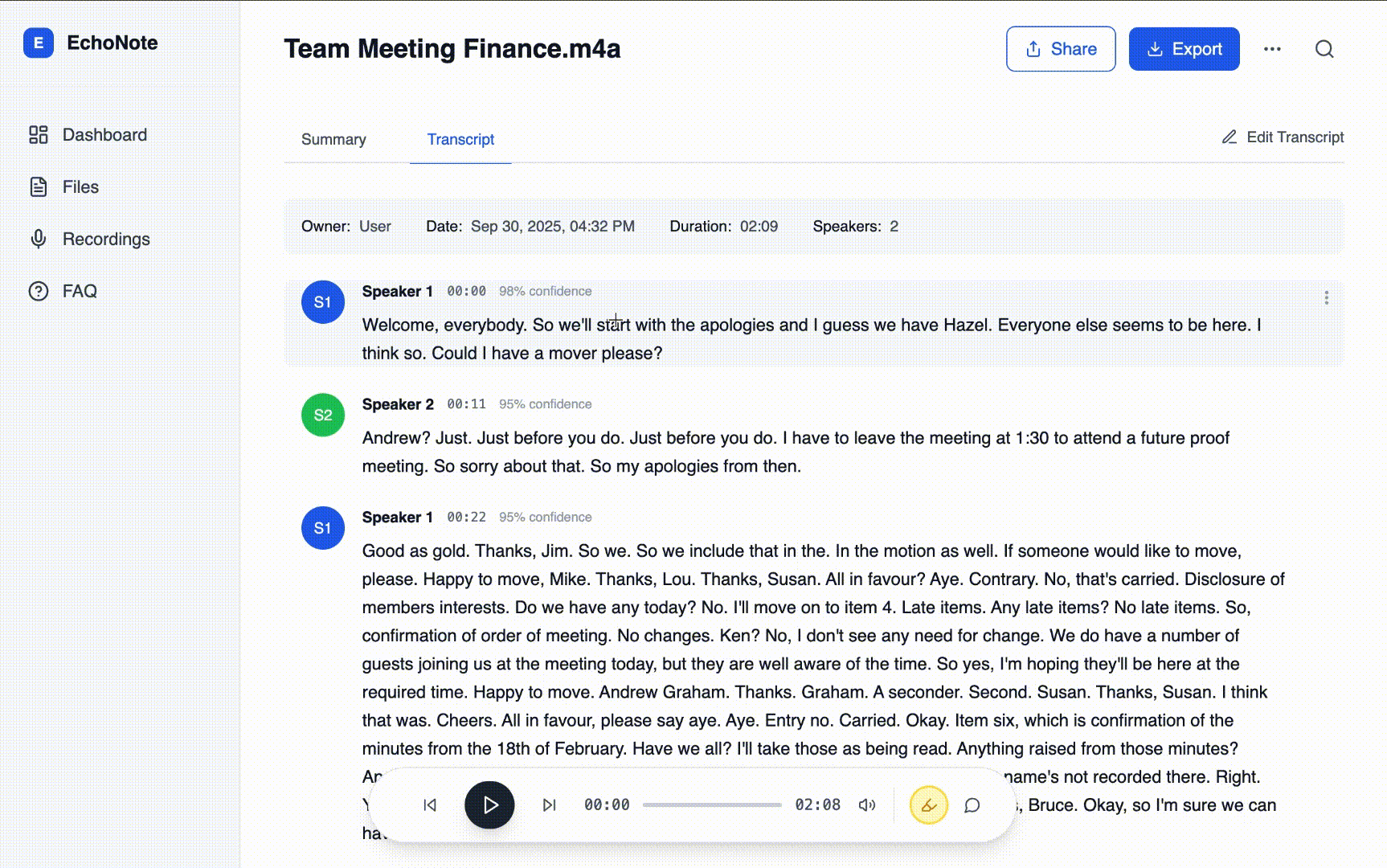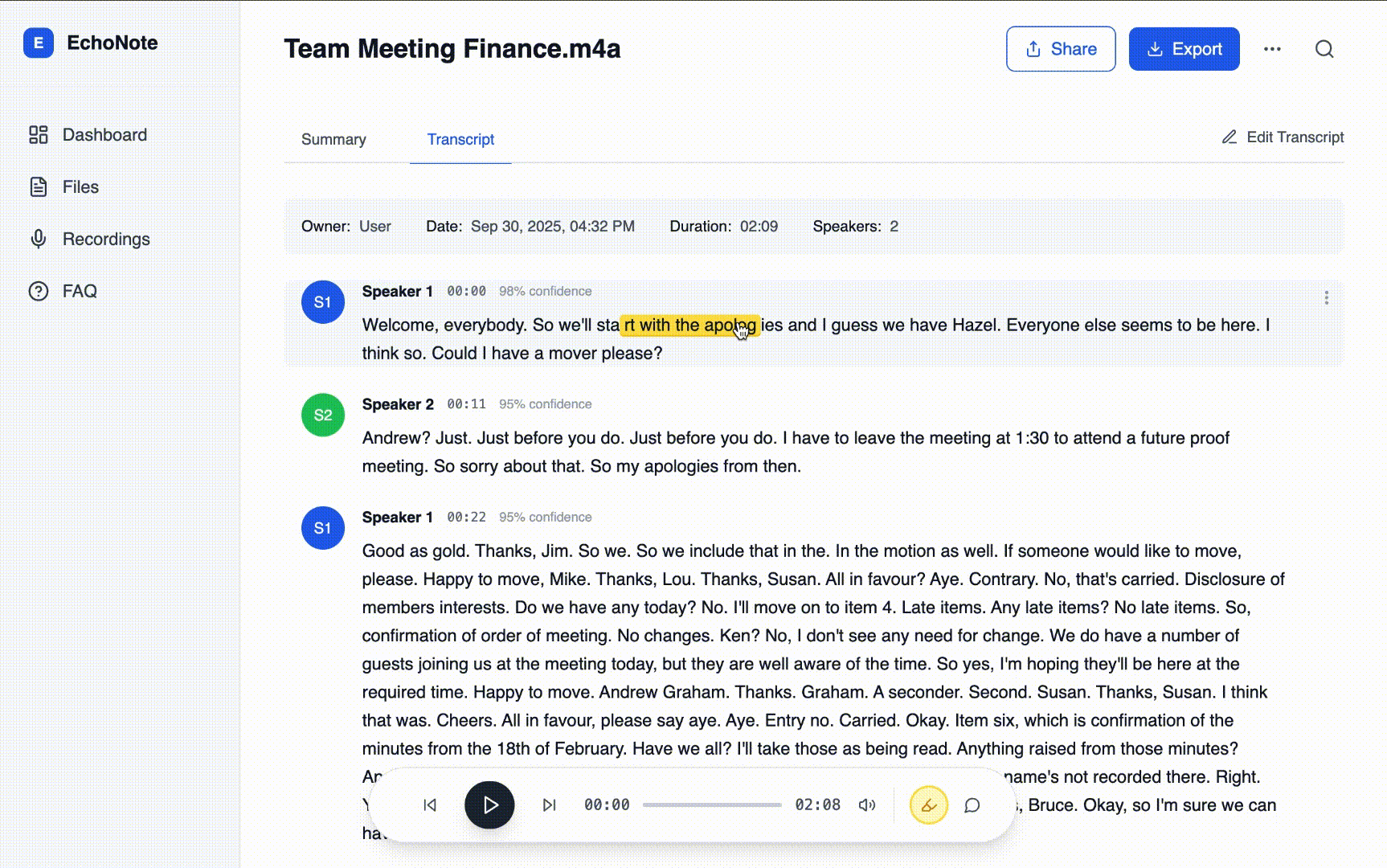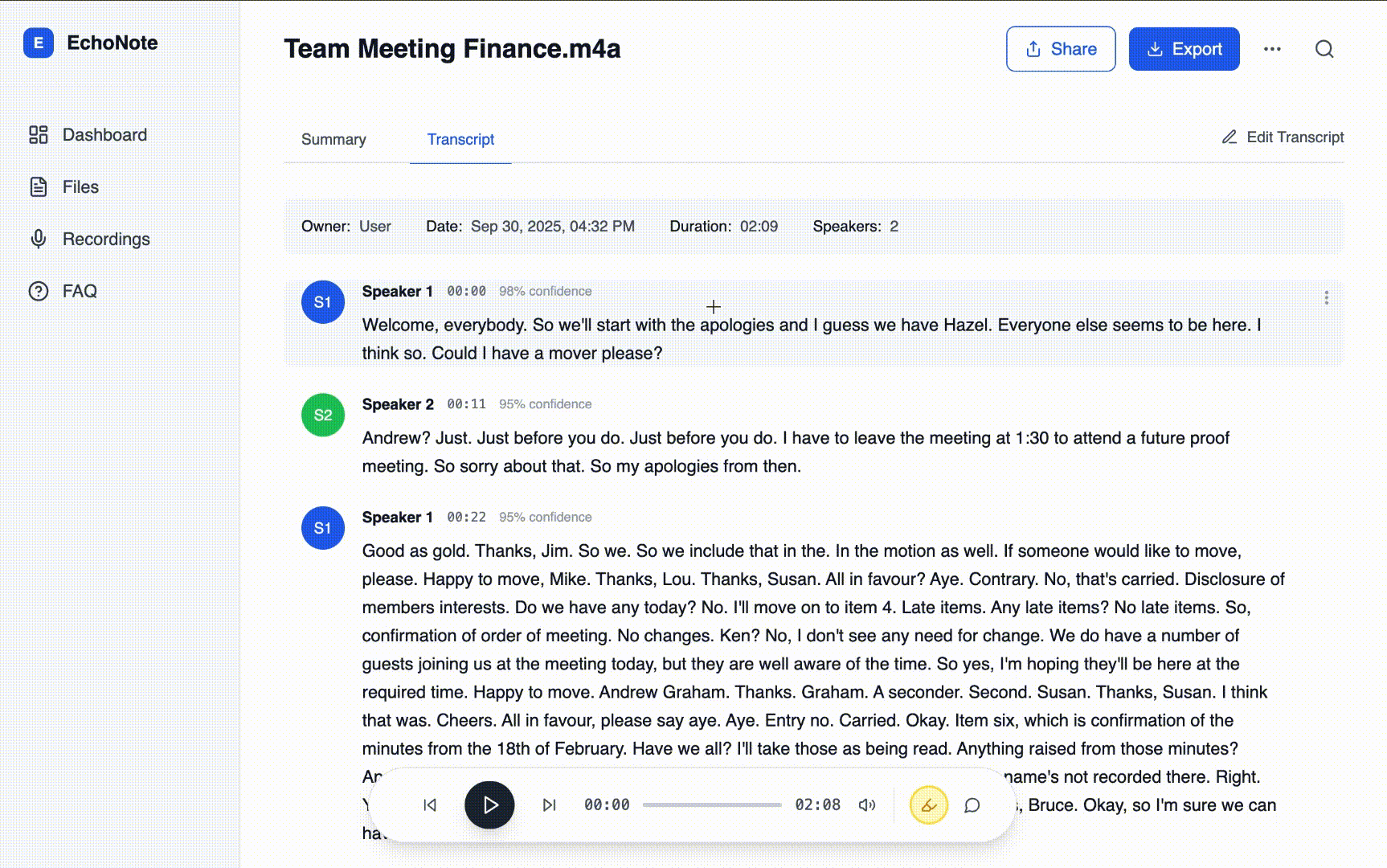
2.Auto-identify and label speakers
3.Enable inline transcript editing and highlighting
4.Generate concise AI summaries with timestamps and tags
5.Provide export options to Notion, Google Docs, and PDF
Started in Figma: Created low-fidelity wireframes with mobile-first layouts
Research & Planning: API to use for transcribing. (If no money limitations I will choose Whisper instead)
Flow Mapping: Defined user flows for uploading, transcribing, editing, summarizing, and exporting
v0 Prototype: Started with Lovable, Bolt, and then v0. Built an interactive click-through prototype to visualize the user journey
Local API Mocking: Simulated transcription responses using local JSON files
UI Iteration: Refined layout and interactions based on early feedback and usability patterns
Audio Input & Transcription:
Upload & Record: Developed drag-and-drop and mic recording (mobile-compatible) components easy to use
Progress Feedback: Implemented status indicator during uploads
Supabase Storage: Integrated for uploading and storing audio files and built upload success/error handling to confirm files are saved.
Speech-to-Text API Integration: Ultimately choose Assembly AI API (non-GPT) for converting audio to text
(Google speech to text API at first , then found out only accepting GS not supporting summary...)
Speaker Labeling: Parsed transcript to apply basic speaker separation (e.g., Speaker 1, Speaker 2)
Transcript Interface
Editable Transcripts: Built inline editing system with autosave support
Highlight System: Added tap-to-highlight functionality with badge tagging (e.g., Important, Action)
Mobile Responsiveness: Tailwind CSS used to ensure smooth experience on mobile and tablet
Cached transcripts and metadata in Supabase Database: for persistence and quick retrieval.
Lightweight Summary Logic: Used simple heuristics or transcript structure (e.g., paragraph segmentation, keyword detection) to generate summaries
Timestamped Highlights: Associated key points with their corresponding audio timestamps
Speaker Insights: Displayed talk-time distribution per speaker as basic insights
Export Modal: Built modal interface with selectable export options (Google Docs, Notion, PDF, Local Save)
(only implement opening the save to ...screen modal)
User Testing: Conducted quick feedback sessions with early users to test core flows
UI Enhancements: Improved visual spacing, font hierarchy, and transitions
Error States: Added fallback messaging and error recovery for failed transcriptions or exports
Rate Limiting: Limited export operations per user to prevent abuse during MVP
Cross-Device Testing: Verified usability across breakpoints and devices
Edit Notes, Summary, Action Items & Transcript: According to user needs (Added function)
Thank you for reading this case study! If you’re interested, feel free to check out my other projects in "WORKS"